
Ansible isn't enough
Ansible for orchestration, not for logic
While the practice of configuration management is less prevalent these days due to the rise of infrastructure-as-code and immutable infrastructure, it is still a worthwhile skill to have your arsenal.
Ansible is a common first choice due to its low barrier to entry, as it boasts the following:
- Agentless design - no prerequisites to getting started
- Simple YAML syntax
- Rich library of existing modules & roles
- Easy to understand sequential playbook paradigm
- Declarative & idempotent roles
- Ease of orchestrating changes across multiple hosts at once
Too much of a good thing
I’ve witnessed the scenario people where somebody will learn how to use Ansible for one task and then go all-in, making it the only tool they ever use.
While I acknowledge that there’s benefit in becoming proficient in a tool, sometimes familiarity can cloud our judgement, and instead of finding the most effective means of achieving the goal, we end up forcing a square peg into a round hole.
It’s really difficult to understand when too much is enough, as we can become blind to the concessions and workarounds we implement in the name of completing the task, especially if we don’t have experience with any alternatives.
This problem isn’t unique to Ansible, but I’ve witnessed its misuse and want to share some anti-patterns and indicators that it’s time to branch out a little.
If the only tool you have is a hammer, you tend to see every problem as a nail
Being prepared 🗒️
Before we dive into writing any kind of automated workflow, we should always develop a high-level plan for it. The idea is to tackling each stage in isolation, and producing compatible output for the next stage (eg. json).
This lets us identify the right tool at every stage, and then we can compose the overall pipeline.
Ultimately you might decide upon an Ansible playbook as a means of centrally managing & co-ordinating this workflow - this is what playbooks excel at - but we shouldn’t start with an Ansible-first mindset as this can lead to major tunnel vision.
Reading the warning signs ☢️
Overuse of localhost
A big chunk of Ansible’s power comes from its idempotent modules, coupled with the library of readily-available modules & roles which can do the majority of the heavy lifting for us.
Another core concept is running playbooks against an ‘inventory’ of hosts. Because of this, Ansible really excels when co-ordinating changes and running complex workflows across multiple remote machines.
By not leveraging the execution engine component of Ansible, we’re essentially writing in a more restrictive framework, with all the idiosyncracies and boilerplate that comes with it, without a lot of the benefit.
Obviously, if you are running an entire playbook locally - ie. provisioning a machine or performing a complex build process - then this might be fine, but I would still suggest that you consider the alternatives, as they may provide a better user experience and ultimately be be more maintainable & testable.
Imperative over declarative
The next code-smell is when there are lots of strictly ordered imperative steps.
You will see this a lot when interacting with external systems that don’t have any idempotency requirements (ie. looking up Kubernetes Pods, making HTTP requests).
While playbooks generally tend to be sequential, they can quickly devolve into a mess of conditional logic, looping and error-handling.
If we take a step back, we can see that we’re replicating all of the paradigms available in a fully-fledged programming language but we’re reaping few of the benefits, and dealing with all of the headache.
Logic or data manipulation in Jinja
A sprinkle of Jinja allows us to make our roles & playbooks more dynamic, but it can also be abused to add complex logic. I think this is the biggest foot-gun in Ansible as this is very subjective.
Firstly, if you want to keep your complex logic inside Ansible, then I’d suggest abstracting it away into a custom filter or module. This allows an escape hatch into Python, which can be easier to encode complex logic, and is ultimately more readable and testable in the log run.
However, I would always suggest re-assessing the use case and seeing if there’s a more appropriate tool. If this is part of a wider playbook, Ansible can still orchestrate running this tool and consuming the resulting data (ie. as json), but it frees us from maintaining complex logic inside of Ansible (especially in Jinja).
Below is a monstrosity that I’ll admit to contributing to a playbook - albeit, not without protest! The entire role was prime candidate for a rewrite using Conftest & Rego.
- name: "check_cronjobs | Set fact jobs_list" # noqa: jinja[spacing] when: - jobs_list_output is defined - jobs_list_output.resources | length > 0 set_fact: cronjob_jobs: | {%- set jobs = [] -%} {%- for job in jobs_list_output.resources if job.metadata.ownerReferences is defined -%} {%- set owner_ref = job.metadata.ownerReferences | first | default({}) -%} {%- if owner_ref.kind is defined and owner_ref.kind == "CronJob" %} {%- set data = { "job_name": job.metadata.name, "cronjob_name": owner_ref.name, "start_time": job.status.startTime, "completion_time": None, "status": "Complete", "failure_reason": None, } -%}
{#- Skip this Job if it is too old -#} {%- set today = (ansible_date_time.date | to_datetime('%Y-%m-%d')).date() -%} {%- set job_start_date = (job.status.startTime | to_datetime("%Y-%m-%dT%H:%M:%SZ")).date() -%} {%- if (today - job_start_date).days > 1 -%} {%- continue -%} {%- endif -%}
{%- if job.status.completionTime is defined %} {%- do data.update({ "completion_time": job.status.completionTime }) -%} {%- endif -%}
{#- NOTE: job.status.conditions is a single item array containing the last condition of the Job https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.25/#jobstatus-v1-batch -#}
{#- NOTE: When testing locally, I've seen it fail, saying that 'conditions' does not exist. I'm not sure if this is a nascent Job or some other transient error, but this doesn't re-occurr so I've been unable to undertand why it is happening -#} {%- if job.status.conditions is not defined -%} {%- continue -%} {%- endif -%}
{%- set condition = job.status.conditions | first -%} {%- if not (condition.type == "Complete" and condition.status == "True") -%} {%- do data.update({ "status": "Failed", "failure_reason": condition.message }) -%} {%- endif -%}
{%- do jobs.append(data) -%} {%- endif -%} {%- endfor -%} {{ jobs }}Real-world scenarios I’ve encountered
Below are some scenarios that I’ve witnessed which definitely over-step the line of where Ansible should be used. These roles & playbooks were difficult to understand & maintain, were brittle to run and were also very slow.
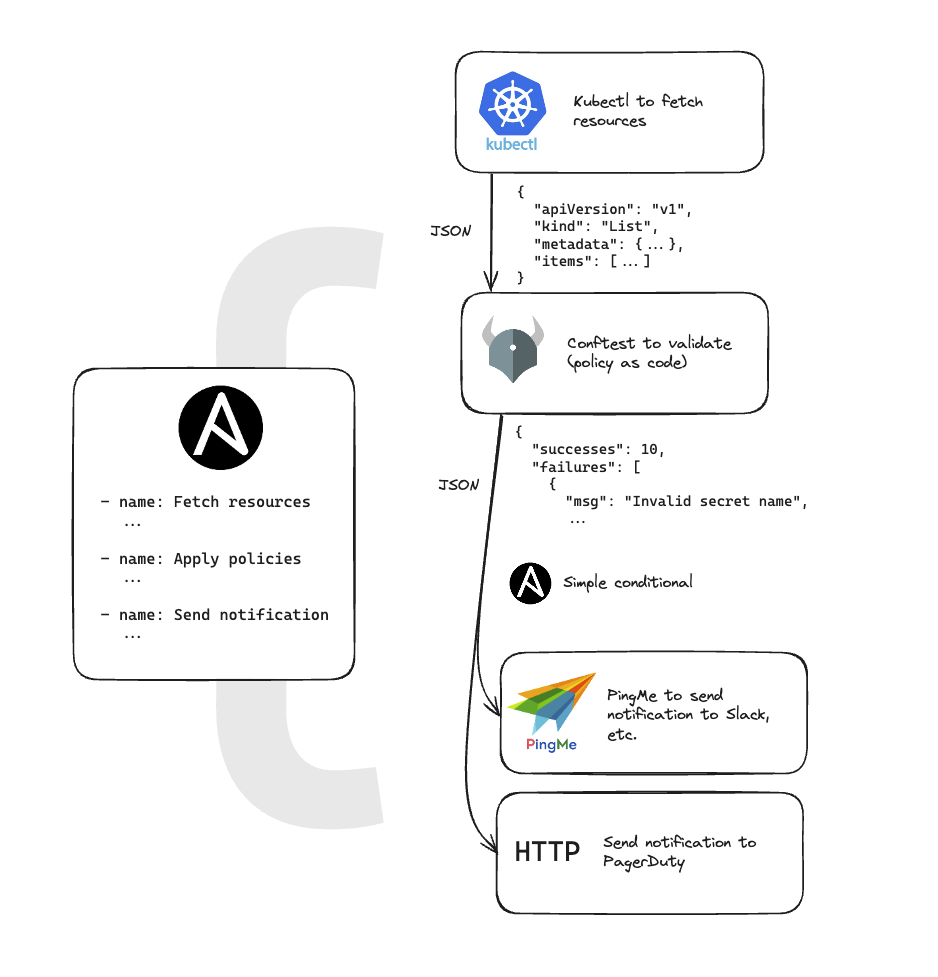
Validating infrastructure resources (AWS & Kubernetes)
The entire thing was done in Ansible which consisted of…
- Data retrieval
- Complex filtering & parsing
- Looping over the parsed data and performing bespoke validations & comparisons against another data set (the expected state)
- Parsing the resulting data into a report
This ultimately suffered from a tonne of boilerplate and complex Jinja blocks.
Tackling this from the ground-up, I would suggest…
| Stage | Proposal |
|---|---|
| Data fetching | aws cli, kubectl, appropriate Golang SDKs |
| Data parsing & validation | Conftest is a clear winner |
| Building a report | Something like PingMe or potentially stick with Ansible now that most of the heavy lifting is done |
Performing ad-hoc health checks for a loadbalancer
This consisted of performing some HTTP requests to different endpoints on a loadbalancer and parsing the results.
Immediately, I think that it would be better to delegate this to a dedicated service that is always performing these checks, such as Prometheus blackbox exporter or a hosted service such as GCP Uptime checks.
If we’re treating this more like an on-demand test suite, the then a tool purpose built
for this such as Hurl is probably a good choice, or we can even write
a test suite in Go that leverages go test.
Performing a multi-node database failover
This is actually a really good use of Ansible!
Being able to co-ordinate steps across multiple nodes while maintaining state is precisely what Ansible is made for.
However, in this scenario, I’d still suggest that some of the more complex logic should be abstracted out into specific scripts so that they can be run and tested in isolation.
Alternatives
The following might be good alternatives if you don’t need everything Ansible provides (good and bad).
Alternative - Taskfile
Task is as a single binary, which lets write and run
Taskfile.yamls. In a scenario where we’re simply running sequential stages on
a single host, this might be enough, meaning we don’t need to even touch Ansible.
This is essentially a modern take on Make, that is data-driven and doesn’t add
any arcane syntax. As well as this, dependency ordering and parallelism are
available out of the box.
Alternative - A custom shell script or CLI tool
This option should be approached carefully as it’s ultimately more of a burden to maintain, but at the same time this approach provides the most flexibility.
The user experience from providing bespoke subcommands, arguments and flags as well as help docs and auto-completion is way above that of running an Ansible playbook.
And it’s really not that hard to get started with the likes of
Viper (Go) or Clap (Rust),
which can ultimately provide a portable, statically-linked binary, or they can be run
from source (go run, cargo run, etc.).
Conclusion
Don’t be afraid to branch out and assess other tools.
You can still keep your core in Ansible if it’s a good fit, but delegate tasks to the best tools for the job!